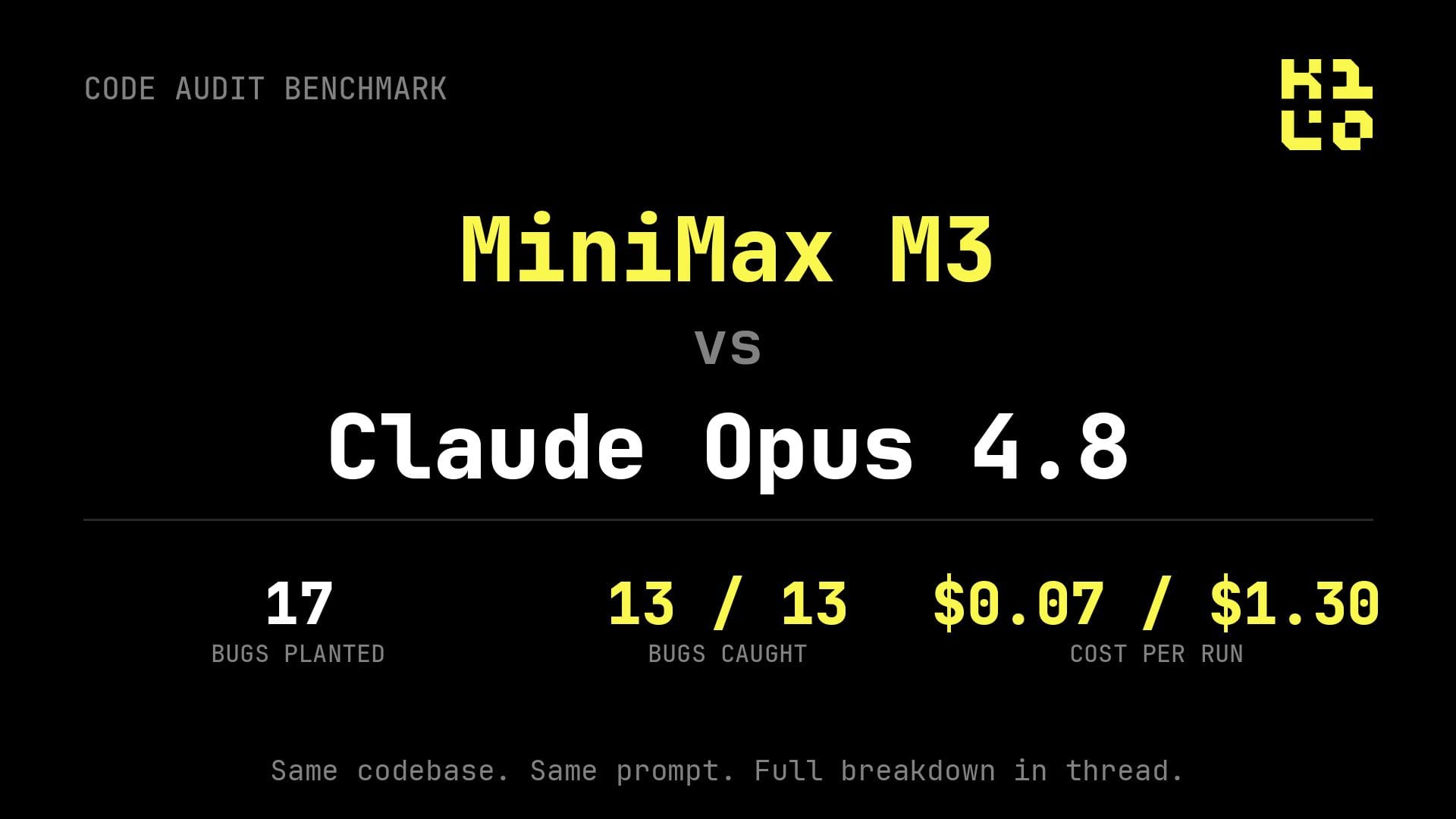
Minggu ini saya review sebuah hasil tes yang cukup bikin saya terdiam.
Bukan tes yang fancy. Cuma satu task sederhana: suruh dua model deteksi bug dari kode yang sama.
Saya baca hasilnya dua kali. Terus duduk diam sebentar.
Oke tapi bedanya hampir 50x, kan?
Ya. Dan ini bukan anomali.
Kalau lihat data resminya, gap ini bahkan lebih ekstrem dari yang kelihatan. Di harga standar, Claude Opus 4.8 dibanderol $5 per juta input token dan $25 per juta output token. MiniMax M3? $0.30 input dan $1.20 output — dan itu sebelum diskon promo 50% yang lagi jalan sekarang. Artinya selisihnya bisa sampai 20x di output, bahkan lebih di kondisi tertentu.
Kalau kamu cuma pakai AI sesekali buat eksperimen, mungkin angka itu terasa abstrak. Tapi coba bayangin kamu lagi ngebuild produk beneran. Setiap hari ada ratusan, mungkin ribuan API call yang jalan. Kamu ngitung setiap token. Kamu bikin spreadsheet cost projection buat yakin unit economics-nya masuk akal.
Selisih segini bukan cuma angka. Itu beda antara produk yang bisa jalan lama dan produk yang bakar uang sebelum sempat tumbuh.
Dan ini bukan kejutan dadakan
Yang menarik, sinyal ini sebenarnya sudah ada jauh sebelum M3 rilis.
Kilo.ai pernah tes MiniMax M2.7 — generasi sebelumnya — head-to-head sama Claude Opus 4.6. Hasilnya? M2.7 berhasil menemukan semua 6 root cause bug dan semua 10 celah keamanan yang sama persis dengan Opus 4.6.
Sembilan puluh persen kualitas, tujuh persen biaya. M3 sekarang selangkah lebih jauh lagi. Di SWE-Bench Pro — benchmark software engineering yang diakui industri — M3 skornya 59%, melampaui GPT-5.5 dan Gemini 3.1 Pro, dan mendekati Claude Opus 4.7. Bahkan di BrowseComp, M3 justru mengalahkan Opus 4.7.
Bukan hype. Datanya mulai bicara sendiri.
Tapi tunggu — Opus masih unggul di beberapa hal
Saya tidak mau overpromise di sini.
Untuk task yang kompleks, panjang, dan high-stakes — debugging yang butuh reasoning dalam, refactor besar, atau agentic session yang jalan berjam-jam — Claude Opus masih punya keunggulan nyata. Di benchmark agregat, Opus 4.8 masih memimpin cukup jauh, terutama di multimodal dan grounded reasoning.
Jadi bukan soal "M3 menang, Opus kalah." Framing yang lebih tepat adalah: M3 sudah masuk level yang sama untuk mayoritas task coding sehari-hari, dengan harga yang jauh lebih bisa diterima.
Dan untuk developer yang ngebuild tiap hari, "mayoritas task sehari-hari" itu adalah 90% dari pekerjaan mereka.
Satu hal yang perlu dipertimbangkan: soal data
Ini bagian yang jarang dibahas tapi penting.
MiniMax adalah perusahaan China. Setiap prompt yang dikirim via API mereka berada di bawah yurisdiksi hukum China — termasuk kewajiban di bawah National Intelligence Law 2017. Belum ada insiden terdokumentasi, tapi kalau kamu handle kode proprietary atau data customer, ini risk assessment yang wajar untuk dipertimbangkan.
Untuk use case internal atau kode yang sensitif, ini perlu jadi pertimbangan. Untuk task yang lebih general? Mungkin tidak terlalu jadi masalah. Tapi setidaknya, kamu harus tahu trade-off ini ada.
Lalu kita harus ngapain?
Landscape ini berubah lebih cepat dari yang kita kira. Setahun lalu, percakapan ini mungkin belum relevan. Sekarang sudah sangat relevan.
Satu framework yang mulai masuk akal untuk banyak tim: gunakan M3 sebagai default untuk bulk of agentic dan coding work sehari-hari, simpan Opus untuk task yang memang butuh kualitas ekstra di mana cost of failure-nya tinggi.
Bukan soal loyalitas ke model tertentu. Bukan soal mana yang lebih keren di atas kertas. Ini soal resource allocation yang masuk akal.
Model China tidak bisa lagi dianggap sebelah mata. Bukan karena klaim mereka. Tapi karena sekarang datanya ada, tesnya bisa direplikasi, dan harganya bicara sendiri.
Kalau kamu belum pernah serius nyoba — mungkin sekarang waktu yang tepat.